
This post continues a series on hybrid architectures that combine local Small Language Models (SLMs) with cloud Large Language Models (LLMs). We have already looked at the Minions pattern, which offloads bulk text extraction to a local model to reduce cloud API costs, and the SLM-default, LLM-fallback pattern, where a local model handles the majority of queries and only escalates to the cloud when confidence is low. Today we look at a third pattern: Chain of Agents (CoA), introduced in the paper “Chain of Agents: Large Language Models Collaborating on Long-Context Tasks” by Wang et al. (2024). Where the previous patterns were primarily motivated by cost, CoA is motivated by a different challenge - what happens when your document is simply too long to fit into any model’s context window?
The Long-Context Problem 🔗
Modern LLMs have grown impressively large context windows - some claiming hundreds of thousands of tokens. In practice, simply stuffing a long document into a prompt does not produce reliable results. Research has consistently shown that models struggle to attend to information spread across a very long context, a phenomenon commonly described as “lost in the middle”: relevant facts near the beginning or end are recalled more reliably than those buried in the middle of a large input. As documents grow into research corpora, legal files, codebases, or multi-chapter books, even the most generous context window becomes a liability rather than an asset.
The naive mitigation - chunking the document and querying each chunk independently - loses inter-chunk coherence. A fact established in chunk 1 may be critical for interpreting something in chunk 4, but a model that only sees chunk 4 has no way to know. This is exactly the gap Chain of Agents addresses.
How Chain of Agents Works 🔗
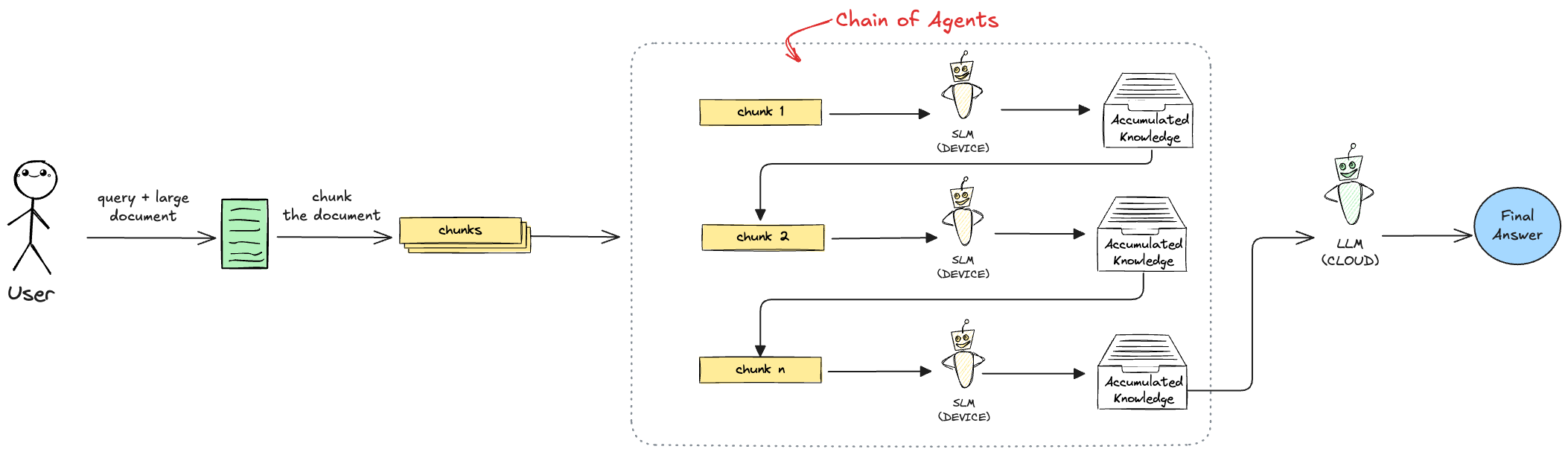
CoA introduces a two-stage architecture with two roles: Worker agents and a Manager agent.
In Stage 1, the document is split into sequential chunks and a chain of Worker agents is created - one per chunk. Workers execute in order. Each Worker receives its assigned chunk along with a Communication Unit (CU): a compact running summary of everything the previous Workers have found. The Worker reads its chunk, integrates it with the incoming CU, and produces an updated CU that it passes to the next Worker in the chain. The first Worker starts with an empty CU; the last Worker’s output is the final CU, containing accumulated evidence from the entire document.
In Stage 2, the Manager agent receives the final CU and uses it to synthesize a direct answer to the user’s query. The Manager never reads the raw document - it reasons only over the distilled CU the Workers produced.
This sequential pass preserves cross-chunk coherence in a way that independent parallel queries cannot. A fact from an early chunk propagates forward through the CU and remains available to every subsequent Worker. The division of labour also maps naturally onto a hybrid setup: Workers performing the repetitive extraction work are a good fit for a local SLM, while the Manager performing high-level synthesis justifies the cost of a cloud LLM.
I like to refer to this pattern as the “law-firm model” - the document is first processed by paralegals (Workers) who distill the key facts into a memo (CU), which is then given to the senior partner (Manager) to produce the final legal advice (answer). Or maybe I just watched too many episodes of Suits recently.
In this demo we use:
- Workers: Phi-4-mini-instruct (8-bit quantized), running locally via Apple’s MLX (the associated demo code on Github also contains the ability to switch to Foundry Local as a cross-platform backend alternative).
- Manager: a cloud LLM deployed in Azure AI Foundry.
- Orchestration: my favorite agentic framework, Microsoft’s Agent Framework.
The demo processes the same short history of quantum mechanics text used in previous posts in this series, but this time the task is a richer synthesis question that requires understanding the full arc of the document rather than spotting isolated facts.
Implementation 🔗
Let’s build this step by step. Dependencies:
pip install mlx-lm python-dotenv agent-framework
The environment variables needed:
AZURE_AI_PROJECT_ENDPOINT=<your Azure AI Foundry project endpoint>
AZURE_AI_MODEL_DEPLOYMENT_NAME=<your Azure AI Foundry model deployment name e.g. gpt-5.4>
LOCAL_BACKEND=mlx
1. The Communication Unit and Helper Utilities 🔗
The CU is just a string - the only state that flows between Workers. Two small utilities support it.
ensure_stateless prevents the Agent Framework’s chat client from accumulating a growing conversation history across separate worker invocations. Since each Worker is a fresh, stateless processing step, we only want the client to see the single prompt we craft:
def ensure_stateless(msgs):
return [msgs[-1]]
truncate_cu keeps the CU within a character budget. Without this, as Workers accumulate findings the CU grows, gradually crowding out the new chunk in the SLM’s limited context window. When the limit is exceeded, we keep the tail of the CU - the most recent findings carry the fullest accumulated context:
MAX_CU_CHARS = 1500
def truncate_cu(cu: str, limit: int = MAX_CU_CHARS) -> str:
if len(cu) <= limit:
return cu
return "..." + cu[-(limit - 3):]
2. The Worker Executor 🔗
The WorkerExecutor wraps one chunk of the document and implements the Worker role from the paper. Its process_chunk handler receives the incoming CU from the previous Worker (or an empty string for the first Worker), constructs a prompt that presents the chunk, the current CU, and the user query, generates an updated CU using the local SLM, and sends it forward.
The prompt structure follows the query-aware template from the paper (Table 9). Crucially, the question is shown to the Worker even though it is not answering it yet - this keeps the extraction focused on evidence that will be relevant to the final answer:
from agent_framework import Executor, handler, Message, WorkflowContext
class WorkerExecutor(Executor):
def __init__(self, name: str, client, query: str, chunk: str, worker_idx: int, total_workers: int):
super().__init__(id=name)
self.client = client
self.query = query
self.chunk = chunk
self.worker_idx = worker_idx
self.total_workers = total_workers
@handler
async def process_chunk(self, message: str, ctx: WorkflowContext[str]):
previous_cu = truncate_cu(message.strip())
if previous_cu:
cu_section = f"Here is the summary of the previous source text: {previous_cu}"
else:
cu_section = "There is no previous summary yet - this is the first chunk."
prompt = (
f"{self.chunk}\n\n"
f"{cu_section}\n\n"
f"Question that will be answered later: {self.query}\n\n"
"You need to read the current source text and the summary of the previous source text "
"(if any) and generate a summary to include them both. "
"Later, this summary will be used for other agents to answer the question. "
"So please write the summary that can include the evidence for answering the question. "
"Do NOT invent or infer anything not explicitly stated in the source text or previous summary. "
"Output only the updated factual summary, 3-5 sentences, no commentary."
)
response = await self.client.get_response([Message("user", [prompt])])
output_text = response.messages[-1].text.strip()
print(f"\n [{self.id} ({self.worker_idx}/{self.total_workers})] Chunk processed. CU length: {len(output_text)} chars")
print(f" {'-'*60}\n {output_text}\n {'-'*60}")
await ctx.send_message(output_text)
3. The Manager Executor 🔗
The ManagerExecutor implements Stage 2. It receives the final CU and synthesizes a direct answer. Its prompt explicitly acknowledges that it is working from a summary rather than the original text - this primes the cloud model for the synthesis task rather than a retrieval task:
class ManagerExecutor(Executor):
def __init__(self, name: str, client, query: str):
super().__init__(id=name)
self.client = client
self.query = query
@handler
async def synthesize(self, message: str, ctx: WorkflowContext[str]):
final_cu = message.strip()
prompt = (
"The following are given passages. However, the source text is too long "
"and has been summarized. You need to answer based on the summary:\n\n"
f"{final_cu}\n\n"
f"Question: {self.query}\n\n"
"Answer:"
)
print(f"\n\n ☁️ {self.id}:\n ", end="", flush=True)
response = await self.client.get_response([Message("user", [prompt])])
print(response.messages[-1].text.strip())
4. Building the Chain 🔗
With both executor types defined, the main function loads the document, creates a Worker per chunk, and wires them into a linear chain terminating at the Manager. The workflow is kicked off with an empty string as the initial CU - matching Algorithm 1 from the paper (CU_0 ← empty string):
async def main():
with open("quantum_mechanics_history.txt", "r", encoding="utf-8") as f:
full_text = f.read()
lines = [l for l in full_text.strip().split("\n") if l.strip()]
chunk_size = 2
document_chunks = ["\n".join(lines[i:i+chunk_size]) for i in range(0, len(lines), chunk_size)]
query = "How did quantum mechanics evolve from Planck's initial hypothesis to a complete mathematical framework? Trace the key contributors and what each one added."
print(f"❔ Query: {query}")
print(f"📄 Document split into {len(document_chunks)} sequential chunks.\n")
local_config = LocalGenerationConfig(max_tokens=250, temp=0.1, repetition_penalty=1.15)
local_client = create_local_client(
model_path=os.environ.get("LOCAL_MODEL_PATH", "phi-4-8bit"),
generation_config=local_config,
message_preprocessor=ensure_stateless,
)
async with AzureCliCredential() as credential:
manager = ManagerExecutor(
name="Cloud_Manager",
client=FoundryChatClient(
project_endpoint=os.environ.get("AZURE_AI_PROJECT_ENDPOINT"),
model=os.environ.get("AZURE_AI_MODEL_DEPLOYMENT_NAME"),
credential=credential
),
query=query
)
workers = [
WorkerExecutor(
name=f"Worker_{i+1}",
client=local_client,
query=query,
chunk=chunk,
worker_idx=i+1,
total_workers=len(document_chunks)
)
for i, chunk in enumerate(document_chunks)
]
builder = WorkflowBuilder(start_executor=workers[0])
for i in range(len(workers) - 1):
builder.add_edge(source=workers[i], target=workers[i+1])
builder.add_edge(source=workers[-1], target=manager)
workflow = builder.build()
print("🚀 Starting Chain...\n")
async for _ in workflow.run("", stream=True):
pass
print("\n\n✅ Workflow Complete.")
The WorkflowBuilder is the same component used in other patterns in this series. Here it is doing something structurally different from a conditional branching graph: we are wiring edges in a strict linear sequence, creating a directed chain Worker_1 → Worker_2 → … → Worker_N → Cloud_Manager. Each edge is unconditional - the CU simply flows forward.
Running the Demo 🔗
Running the demo produces the following output. Three Workers process the document in sequence - watch the CU grow from a summary of the first two contributors into a comprehensive timeline of the entire field:
❔ Query: How did quantum mechanics evolve from Planck’s initial hypothesis to a complete mathematical framework? Trace > the key contributors and what each one added. 📄 Document split into 3 sequential chunks.
[Local Backend: mlx] Loading model: mlx-community/Phi-4-mini-instruct-8bit 🚀 Starting Chain…
[Worker_1 (1/3)] Chunk processed. CU length: 747 chars
Quantum mechanics began with Max Planck’s 1900 hypothesis that energy-radiating atomic systems could be divided into discrete quanta to explain black body radiation. Albert Einstein expanded on this in 1905, proposing that light consists of discrete quantum particles called photons to explain the photoelectric effect. These contributions laid foundational concepts for a complete mathematical framework of quantum mechanics, which would later be developed by key figures such as Niels Bohr with his model of the hydrogen atom, Werner Heisenberg’s matrix mechanics formulation in 1925-26 and Erwin Schrödinger with his wave equation, culminating into a comprehensive theory that describes the behavior of particles at atomic and subatomic levels.
[Worker_2 (2/3)] Chunk processed. CU length: 668 chars
Quantum mechanics evolved from Max Planck’s hypothesis of energy quanta to explain black body radiation, which was > expanded by Albert Einstein who proposed that light consists of photons. Niels Bohr introduced a model for the hydrogen atom with quantized electron orbits, and Louis de Broglie hypothesized matter waves for all particles. Werner Heisenberg developed matrix mechanics, and Erwin Schrödinger formulated the wave equation to describe particle behavior at atomic levels. These contributions built a comprehensive mathematical framework for quantum mechanics, explaining phenomena like spectral lines and electron diffraction through discrete energy levels.
[Worker_3 (3/3)] Chunk processed. CU length: 893 chars
Quantum mechanics evolved from Max Planck’s hypothesis of energy quanta to explain black body radiation, which was > expanded by Albert Einstein who proposed that light consists of photons. Niels Bohr introduced a model for the hydrogen atom with quantized electron orbits, and Louis de Broglie hypothesized matter waves for all particles. Werner Heisenberg developed matrix mechanics, and Erwin Schrödinger formulated the wave equation to describe particle behavior at atomic levels. These contributions built a comprehensive mathematical framework for quantum mechanics, explaining phenomena like spectral lines and electron diffraction through discrete energy levels. Key contributors further unified the theory with special relativity, developed rigorous mathematical foundations for quantum mechanics as a linear operator on Hilbert spaces and introduced influential notations like bra–ket.
☁️ Cloud_Manager: Quantum mechanics developed step by step, with each scientist adding a crucial idea:
- Max Planck began it by proposing that energy is emitted and absorbed in discrete packets, or quanta, to explain black body radiation.
- Albert Einstein extended this idea by arguing that light itself is quantized into photons, helping explain effects such as the photoelectric effect.
- Niels Bohr applied quantization to the atom, proposing that electrons in hydrogen occupy fixed, quantized orbits, which explained spectral lines.
- Louis de Broglie generalized wave-particle duality by suggesting that all matter has wave-like properties, > not just light.
- Werner Heisenberg developed matrix mechanics, one of the first full mathematical formulations of quantum mechanics.
- Erwin Schrödinger created wave mechanics through the Schrödinger equation, describing how particles behave at atomic scales and explaining phenomena like electron diffraction and discrete energy states.
These ideas were later unified and strengthened:
- Quantum theory was connected with special relativity.
- Its mathematics was placed on a rigorous basis using linear operators on Hilbert spaces.
- New powerful notation, especially bra–ket notation, helped formalize and simplify the theory.
So, quantum mechanics evolved from Planck’s simple quantization idea into a complete mathematical framework through successive contributions: quantized energy, photons, quantized atomic orbits, matter waves, matrix mechanics, > wave mechanics, and finally a rigorous abstract mathematical structure.
✅ Workflow Complete.
The CU starts as Worker 1’s summary of Planck and Einstein and steadily compounds, with each Worker integrating the previous summary with its new chunk. By Worker 3 the CU covers the entire arc from 1900 to von Neumann’s 1932 textbook. The Manager then has everything it needs to produce a structured narrative without ever seeing the raw document.
Final Thoughts 🔗
Chain of Agents occupies a different point in the design space compared to the patterns explored in previous posts. The Minions pattern decomposes a query into independent atomic jobs that local SLMs execute in parallel across chunks - it optimizes primarily for cost. CoA’s Worker chain is sequential and stateful: each Worker builds on the accumulated knowledge of its predecessors. This makes CoA better suited for questions that require synthesizing a through-line across a document, rather than spotting isolated facts.
The Communication Unit is both the strength and the main engineering concern of the pattern. It must remain compact enough to leave room for the incoming chunk in the SLM’s context window, yet comprehensive enough to preserve the evidence chain. The MAX_CU_CHARS cap and tail-preserving truncation used here are simple heuristics. In production, one might instead instruct the Worker to actively compress the CU - summarizing earlier findings at a higher level of abstraction as the chain grows longer.
The sequential nature also means latency scales with document length. Each Worker must complete before the next begins. For very long documents, this is a real cost; for use cases where coherence across the document is what matters - legal analysis, scientific literature review, long-form narrative understanding - it is usually worth it.
As with the other posts in this series, the full source code is available on GitHub.


